NLP: Tokenization, Stemming, Lemmatization and Part of Speech Tagging
In this blog post, I’ll talk about Tokenization, Stemming, Lemmatization, and Part of Speech Tagging, which are frequently used in Natural Language Processing processes. We’ll have information about how to use them by reinforcing them with applications. Enjoyable readings.

Tokenization
Tokenization is the process of breaking down the given text in natural language processing into the smallest unit in a sentence called a token. Punctuation marks, words, and numbers can be considered tokens. So why do we need Tokenization? We may want to find the frequencies of the words in the entire text by dividing the given text into tokens. Then, models can be made on these frequencies. Or we may want to tag tokens by word type. I’ll mention this while explaining Part of Speech Tagging.
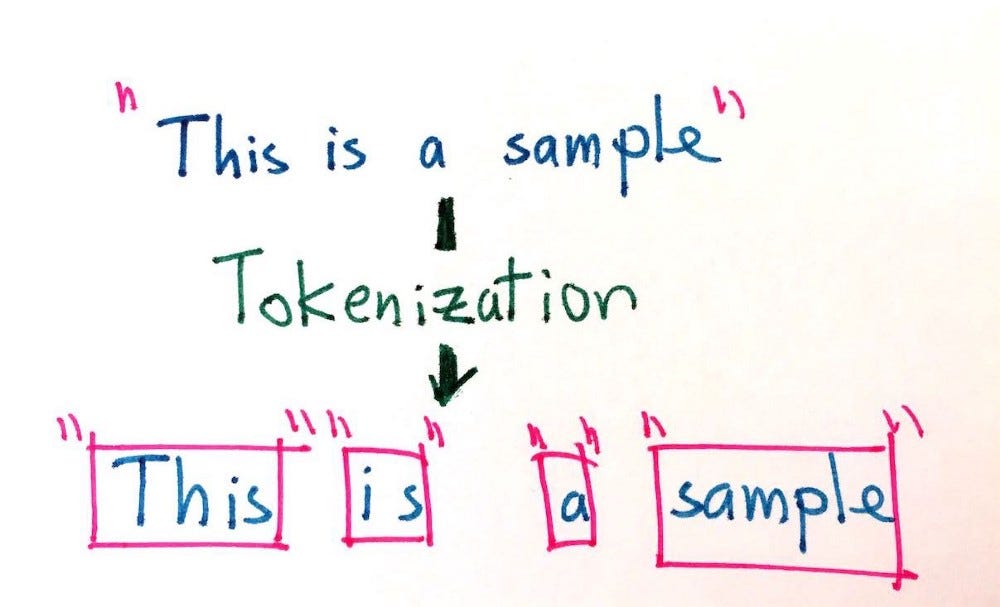
Let’s make an application for Tokenization. We will examine the tokenization process by applying it with 2 different libraries. First, let’s make an example with the TextBlob library. First, we need to download the library.
After downloading the library and importing it, let’s define a text.
In order to do tokenization, we can access tokens by calling words from the TextBlob object. As a result, you will see that the text we have is allocated to tokens as below.
As you can see, we were able to split it into tokens quite simply. Let’s do this with the NLTK (Natural Language Toolkit) library.
As you can see, we have called word_tokenize and sent_tokenize objects from the NLTK library. With sent_tokenize we’ll be able to split the text into sentences. We’ll split it into the same text words with word_tokenize.
The
sent_tokenizefunction uses an instance ofPunktSentenceTokenizerfrom thenltk.tokenize.punkt module, which is already been trained and thus very well knows to mark the end and beginning of sentence at what characters and punctuation.
word_tokenize()function is a wrapper function that calls tokenize() on an instance of theTreebankWordTokenizer class.
Thus, we can do the split into tokens in a very practical way with two different libraries.
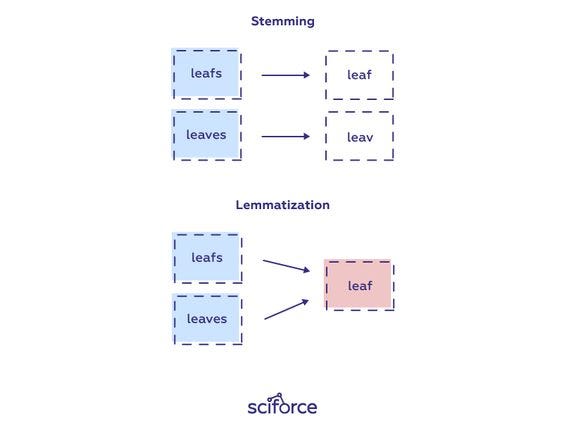
Stemming
Stemming is the process of finding the root of words. Let’s examine a definition made about this.
Stemming is definitely the simpler of the two approaches. With stemming, words are reduced to their word stems. A word stem need not be the same root as a dictionary-based morphological root, it just is an equal to or smaller form of the word.
When you are breaking down words with stemming, you can sometimes see that finding roots is erroneous and absurd. Because Stemming works rule-based, it cuts the suffixes in words according to a certain rule. This reveals inconsistencies regarding stemming. Overstemming and understemming.
Overstemming occurs when words are over-truncated. In such cases, the meaning of the word may be distorted or have no meaning.
Understemming occurs when two words are stemmed from the same root that is not of different stems.
We’ll examine the stemming example with two different algorithms.
- Porter Stemmer (Algorithm details are in this link.)
- Snowball Stemmer (Algorithm details are in this link.)
First, let’s import the PorterStemmer.
Then, let’s define a ps an object that will implement PorterStemmer. After defining the word to be stemming, all that remains is to run the code.
Let’s do a similar process with SnowballStemmer. For this, we do import the SnowballStemmer.
Then, we define the stemmer object. Here, in addition to PorterStemmer, we can also choose in which language we will stemming in SnowballStemmer.
Lemmatization
Lemmatization is the process of finding the form of the related word in the dictionary. It is different from Stemming. It involves longer processes to calculate than Stemming. Let’s examine a definition made about this.
The aim of lemmatization, like stemming, is to reduce inflectional forms to a common base form. As opposed to stemming, lemmatization does not simply chop off inflections. Instead, it uses lexical knowledge bases to get the correct base forms of words.
NLTKprovidesWordNetLemmatizerclass which is a thin wrapper around thewordnetcorpus. This class usesmorphy()function to theWordNet CorpusReaderclass to find alemma.
First, let’s do import NLTK and WordNetLemmatizer.
Let’s see how the lemmatizer works in a single word.
Then we have a text. Let’s break this text down to tokens first. Then let’s apply the lemmatizer one by one on these tokens.
In the first example of Lemmatizer, we used WordNet Lemmatizer from the NLTK library. Let’s do similar operations with TextBlob. As a result, we will reach similar results.
When we apply the ‘lemmatize’ process to the word ‘stripes’, it deletes the ‘s’ suffix and reaches the word ‘stripe’, which is the dictionary form of the word. Now let’s do the same on a sentence.
Thus, we examined how the ‘lemmatization’ process is implemented on both sentences and a single word with two different libraries.
Part of Speech Tagging
Part of Speech Tagging (POS-Tag) is the labeling of the words in a text according to their word types (noun, adjective, adverb, verb, etc.). Let’s look at how it is explained in a definition.

It is a process of converting a sentence to forms — list of words, list of tuples (where each tuple is having a form (word, tag)). The tag in case of is a part-of-speech tag, and signifies whether the word is a noun, adjective, verb, and so on.
Let’s examine the most used tags with examples.
- Noun (N)- Daniel, London, table, dog, teacher, pen, city, happiness, hope
- Verb (V)- go, speak, run, eat, play, live, walk, have, like, are, is
- Adjective(ADJ)- big, happy, green, young, fun, crazy, three
- Adverb(ADV)- slowly, quietly, very, always, never, too, well, tomorrow
- Preposition (P)- at, on, in, from, with, near, between, about, under
- Conjunction (CON)- and, or, but, because, so, yet, unless, since, if
- Pronoun(PRO)- I, you, we, they, he, she, it, me, us, them, him, her, this
- Interjection (INT)- Ouch! Wow! Great! Help! Oh! Hey! Hi!
So, how does POS Tagging works?
POS tagging is a supervised learning solution that uses features like the previous word, next word, is first letter capitalized etc. NLTK has a function to get pos tags and it works after tokenization process.
Let’s understand Part of Speech Tagging with an application. Let’s import the NLTK library and word_tokenize object. When applying this, we first need to split a sentence into tokens. Tagging works after splitting to tokens.
After separating the words in a sentence into tokens, we applied the POS-Tag process. For example, the word ‘The’ has gotten the tag ‘DT’. The word ‘feet’ has been labeled ‘NNS’. You can review this link to investigate in detail what these tags are.
Thank you for reading my blog post. Your suggestions and feedback regarding the content are very important to me. You can indicate your thoughts by commenting. Happy days everyone!
Resources
- https://www.geeksforgeeks.org/nlp-part-of-speech-default-tagging/
- https://pythonexamples.org/nltk-tokenization/
- https://towardsdatascience.com/part-of-speech-tagging-for-beginners-3a0754b2ebba
- https://www.machinelearningplus.com/nlp/lemmatization-examples-python/
- https://www.geeksforgeeks.org/introduction-to-stemming/
- https://www.geeksforgeeks.org/python-nltk-nltk-tokenizer-word_tokenize/
- https://medium.com/@gianpaul.r/tokenization-and-parts-of-speech-pos-tagging-in-pythons-nltk-library-2d30f70af13b
- https://www.geeksforgeeks.org/nlp-how-tokenizing-text-sentence-words-works/
- https://www.geeksforgeeks.org/introduction-to-stemming/
- https://towardsdatascience.com/stemming-lemmatization-what-ba782b7c0bd8
- https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
- https://www.tutorialspoint.com/natural_language_toolkit/natural_language_toolkit_stemming_lemmatization.htm
- https://www.geeksforgeeks.org/nlp-part-of-speech-default-tagging/
- https://medium.com/greyatom/learning-pos-tagging-chunking-in-nlp-85f7f811a8cb
